1:02:28
[꼼꼼한 논문 리뷰] Explaining and Harnessing Adversarial Examples [ICLR 2015] (인공지능 보안/AI Security)
동빈나
1:09:54
[꼼꼼한 논문 리뷰] Towards Evaluating the Robustness of Neural Networks [S&P 2017] (인공지능 보안/AI Security)
1:03:05
[꼼꼼한 논문 리뷰] Towards Deep Learning Models Resistant to Adversarial Attacks [ICLR 2018] (인공지능 보안)
52:55
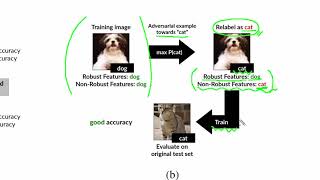
[꼼꼼한 논문 리뷰] Adversarial Examples Are Not Bugs, They Are Features [NIPS 2019] (인공지능 보안)
1:46:14
[꼼꼼한 논문 리뷰] Certified Robustness to Adversarial Examples with Differential Privacy [S&P 2019] (AI보안)
2:22:59
[꼼꼼한 논문 리뷰] Obfuscated Gradients Give a False Sense of Security [ICML 2018] (인공지능 보안)
1:14:21
[꼼꼼한 논문 리뷰] Constructing Unrestricted Adversarial Examples with Generative Models [NIPS 2018] (AI보안)
24:38
[꼼꼼한 논문 리뷰] Adversarial Patch: 스티커를 붙이기만 하면 인공지능이 망가진다! [NIPS 2017] (인공지능 보안/AI Security)