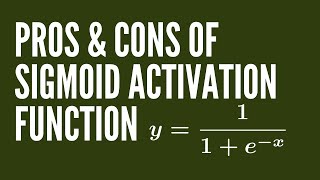5:18
Tensorflow Basics in 5 Minutes | Machine Learning
Bhavesh Bhatt
9:48
TensorFlow 2.0 - Introductory Tutorial
8:22
Build a Simple Neural Network with TensorFlow 2.0 in Google Colab
5:23
Linear Regression with TensorFlow 2.0
8:43
Derivative of the Sigmoid Activation function | Deep Learning
9:06
Pros & Cons of Sigmoid Activation Function
8:57
Tanh Vs Sigmoid Activation Functions in Neural Network
10:11
Rectified Linear Unit (ReLU) Activation Function
5:58
Leaky ReLU Activation Function in Neural Networks
9:24
Why is ReLU a Non-Linear Activation function?
6:26
Importance of Data Normalization in Deep Learning
11:06
Vanishing Gradient explained using Code!
8:18
L2 Regularization with Keras to Decrease Overfitting in Deep Neural Networks
11:19
Advantages of Xavier Initialization in Deep Neural Networks
7:28
Early Stopping in Keras to Prevent Overfitting in Neural Networks
Why dont we initialise the weight of a neural network to Zero? Weight Initialization in Deep Network
8:47
Dropout in Keras to Prevent Overfitting in Neural Networks
7:15
Batch Normalization in Tensorflow/Keras
7:14
Creating Custom Callbacks in Keras
5:28
Accelerating Gradient Descent with Momentum
4:13
Nesterov's Accelerated Gradient
5:27
Understanding RMSProp Optimization Algorithm Visually
4:19
Adam Optimizer or Adaptive Moment Estimation Optimizer
3:17
Softmax Function in Deep Learning
6:49
Derivative of the Tanh Activation function | Deep Learning